常数吞吐量分布式使用示例
常数吞吐量定时器(Constant Throughput Timer)通常用于控制吞吐量,您可以根据压测脚本的业务目的,来选择不同的计算模式。若叠加上分布式施压源,您需要考虑脚本中的配置值及配置模式,以便匹配不同的压测目标模型。本文将从应用场景的角度介绍2种常见的使用模式,以及分布式适配不同计算模式的效果。
背景信息
通过以下示例您可以了解到不同的分布式适配方式。假设使用到2台施压IP,并发为100,脚本上仅1个线程组,其吞吐量目标为每分钟100,计算模式为当前线程(this thread only)。
全局生效即为脚本中设置值为集群整体阈值,施压机会根据使用到的IP数来拆分到单机吞吐量目标值上(即单施压机阈值为脚本中值/IP数),此时场景的总目标吞吐量为2×(100并发/2 )×(100/2)=5000(每分钟)。
单机生效即为脚本中设置值为单台施压机的目标值,不会替换脚本内容,需要注意并发量级与配置值是否匹配。该模式下,场景的总目标吞吐量为2×(100并发/2 )×100=10000(每分钟)。
常见应用场景
通常配置吞吐量控制时,您可以选择Sampler维度或线程组维度(多线程组即全场景维度)即可,不推荐使用其他过于复杂的场景。以下示例中使用了2台施压机IP,线程组总并发100,目标吞吐量每分钟100。
场景一:Sampler吞吐量控制的实现
登录PTS控制台,选择,然后单击JMeter压测。
打开高级设置,在常数吞吐量定时器中选择单机生效。
说明只有上传的脚本中设置了定时器,场景配置中才会出现分布式适配设置的配置框。

JMeter脚本中将该组件(Constant Throughput Timer)置于
Sampler下面。设置Target Throughput为
100,单位为分钟。计算模式选择this thread only,如下图所示。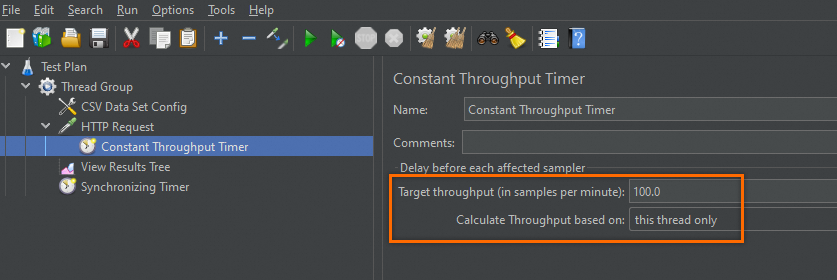
场景二:线程组吞吐量控制的实现
登录PTS控制台,选择,然后单击JMeter压测。
打开高级设置,在常数吞吐量定时器中选择全局生效。
说明只有上传的脚本中设置了定时器,场景配置中才会出现分布式适配设置的配置框。

JMeter脚本中将该组件(Constant Throughput Timer)置于
Thread Group下面。设置Target Throughput为
100,单位为分钟。计算模式选择All active threads in current thread group,如下图所示。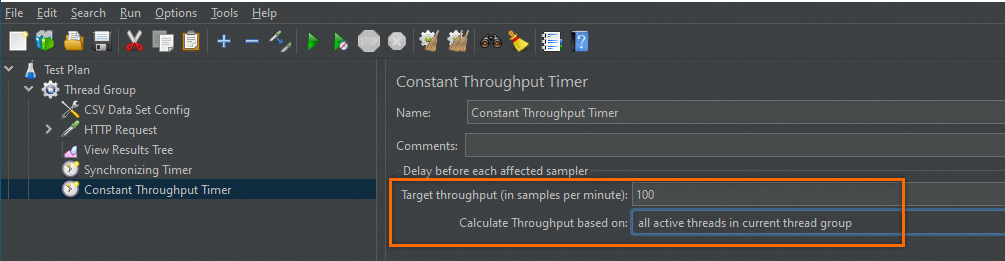
5种计算模式
示例:假设使用单台施压源,2个线程组,即分别含有2个Sampler,分别是100并发和200并发,Target Throughput均是每分钟100。
以下示例仅供参考,具体请以官方文档为准,请参见JMeter官方文档。
基于的计算方式 | 说明 | 其他信息 |
this thread only | 每个线程单独计算,那么总的吞吐量等于并发×Target Throughput。 | 非活跃的线程,没有对应的吞吐量,按照上述示例(每分钟):
|
All active threads | 将设置的吞吐量,分配到活跃的线程上(所有线程组的所有线程),然后这个线程在上次运行自行结束之后,等待合理时间(为了控制吞吐量)再次运行。 | 多线程组的时候,要求其他线程组也有一样的配置按照上述示例:
|
All active threads in current thread group | 将设置的吞吐量,分配到活跃的线程上(当前线程组的活跃线程),然后这个线程在上次运行自行结束之后,等待合理时间(为了控制吞吐量)再次运行。 | 单线程组的时候,与上一个相同。按照上述示例:
|
All active threads(shared) | 将设置的吞吐量,分配到活跃的线程上(所有线程组的所有线程),所有线程都会在所有活跃线程运行结束之后即所有线程结束之后,等待合理时间(为了控制吞吐量)再次运行。 | 类似全场景的多次延迟释放,因为需要等待所有活跃线程运行结束,按照上述示例分析如下:
|
All active threads in current thread group(shared) | 将设置的吞吐量,分配到活跃的线程上(当前线程组的活跃线程),所有线程都会在所有活跃线程运行结束之后即所有活跃线程结束之后,等待合理时间(为了控制吞吐量)再次运行。 | 当前线程组中,活跃线程组中线程结束之后,再等待一点时间运行。
|
其他计算模式的分布式适配情况
基于的计算方式 | 应用场景 | 全局生效 | 单机生效 |
All active threads | 全场景吞吐量控制驱动:多个线程组的业务模型类似,且全场景的吞吐量固定,即可拆分到单个线程组的均匀吞吐量。 | 单机并发线程是50,Target/2替换为脚本中的值,即单机上的吞吐量变成脚本中的一半为每分钟50。全局的吞吐量不变化仍然为每分钟100。当有多个线程组的时候,还会多个线程组累加。 | 单机并发线程是50,单机上的吞吐量为每分钟100,全局吞吐量变为脚本中的值×IP数,即为每分钟200。当有多个线程组的时候,还会多个线程组累加。 |
All active threads(shared) | 全场景吞吐量不区分线程组,略低于多线程组配置值叠加。 | 线程组1配置是100,线程组2配置是200,则全局为150,即两个线程组的均值。 | 线程组1配置是100,线程组2配置是200,则单机为(100+200)/2,全局为300,但是单机多个Sampler达到均衡的时间更长。 |
All active threads in current thread group(shared) | 线程组的吞吐量考虑全局活跃,略低于多线程组配置值叠加。 | 线程组1配置是100,线程组2配置是200,则全局为300,是线程组1和2的配置数累计之和。 | 线程组1配置是100,线程组2配置是200,则单机为100+200,全局为600,但是单机多个Sampler达到均衡的时间更短。 |